Diagnose von Brustkrebs
Um die ethischen Fragestellungen zu verdeutlichen, gibt es hier die Möglichkeit selbst mit verschiedenen Algorithmen des Maschinellen Lernens zu arbeiten.
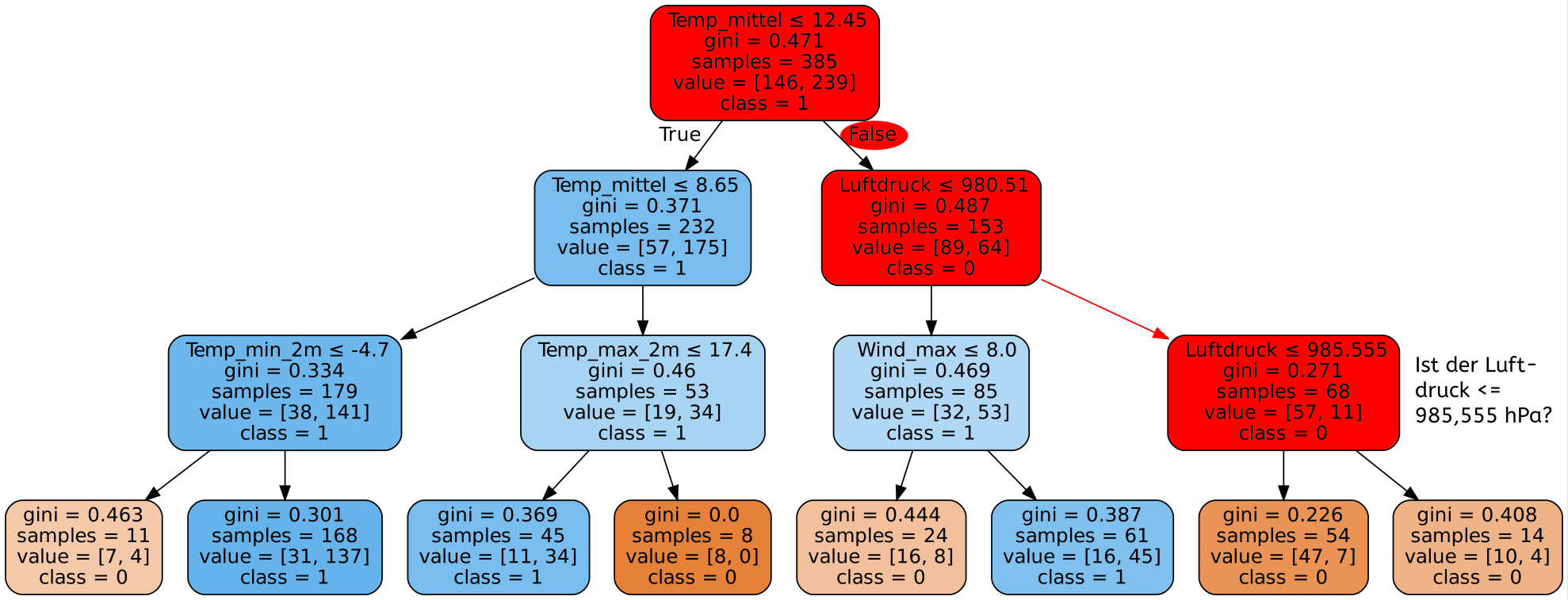
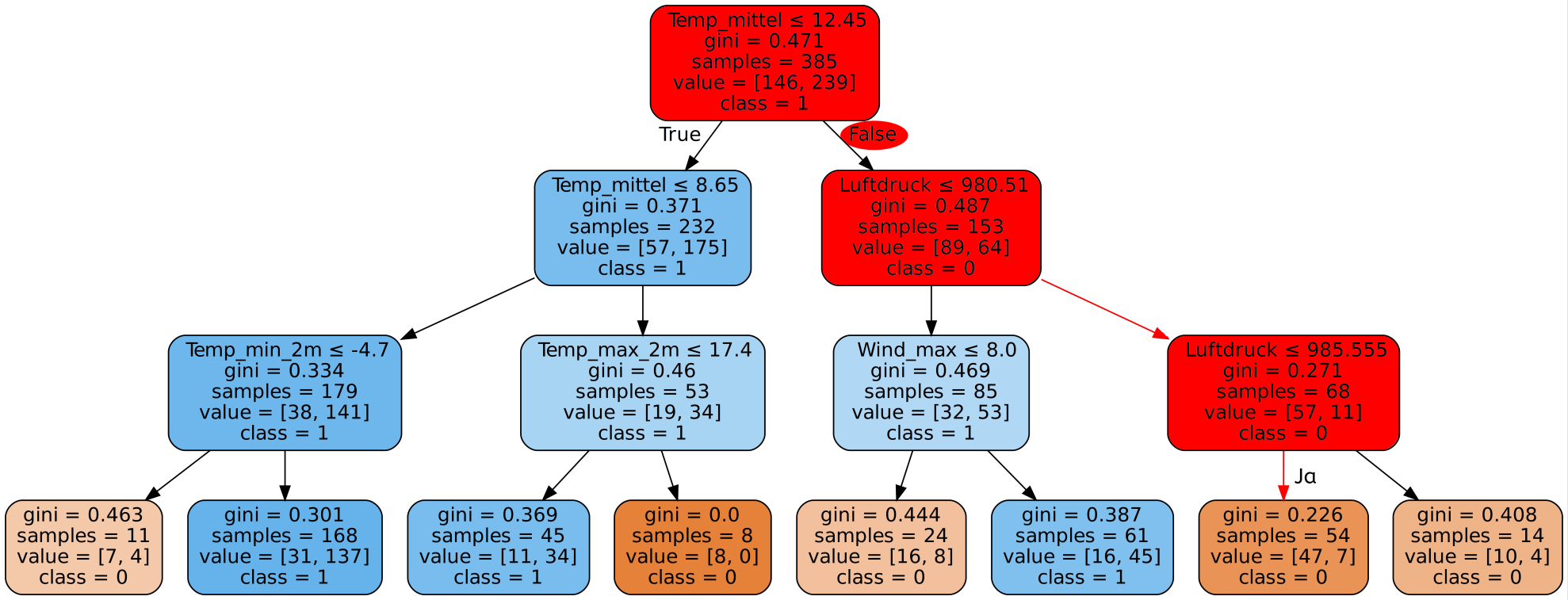
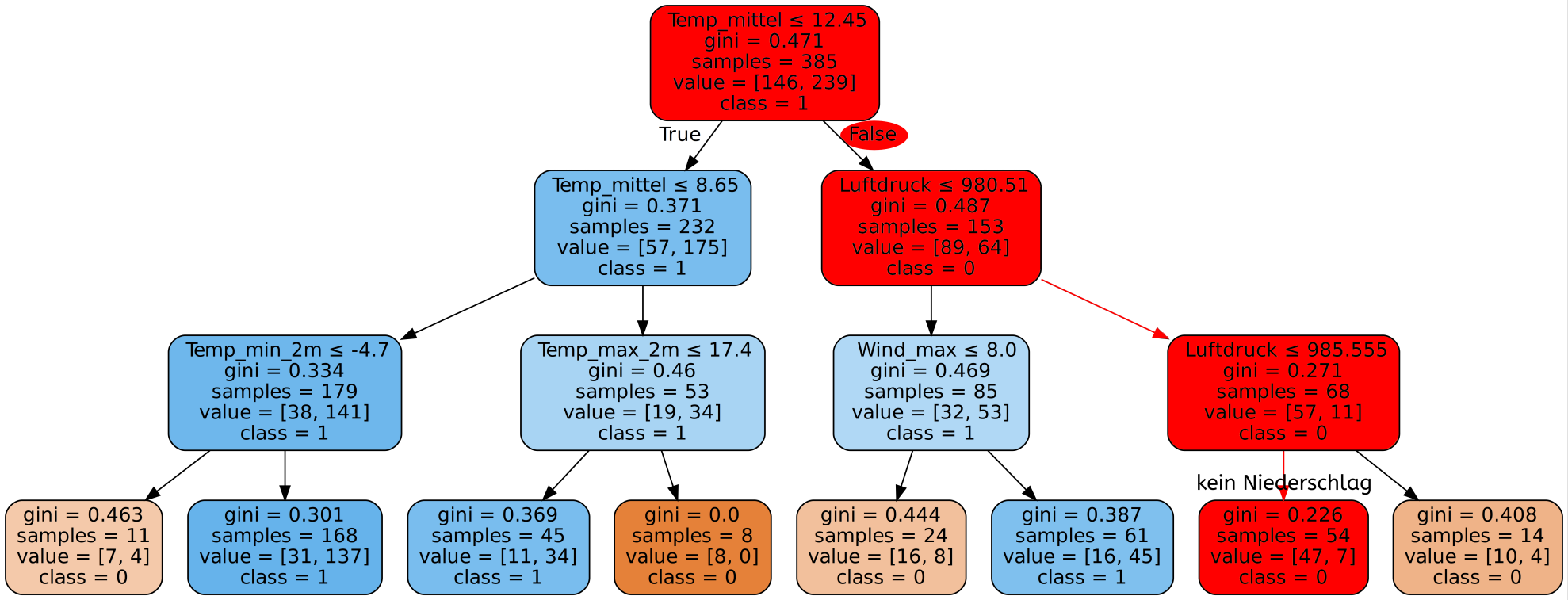
Für die Diagnose von Brustkrebs wurde mit Hilfe einer minimal invasiven Biopsie Gewebematerial aus dem vermuteten Tumor entnommen. Die darin enthaltenen Zellkerne wurden dann auf verschiedene Eigenschaften hin untersucht. Diese Untersuchungen wurden für alle in der Gewebeprobe enthaltenen Zellkerne durchgeführt und dann die jeweiligen Mittelwerte, Standardabweichungen und der schlechteste Wert als ein einzelner Datensatz benutzt.
Die untersuchten Eigenschaften der Zellkerne sind:
Was war nochmal die Standardabweichung?
Tipp: Es hatte was mit Streuung zu tun
- Radius (durchschnittliche Entfernung von der Mitte zum Rand des Zellkerns)
- Textur (wie gleichmäßig ist der Farbverlauf?)
- Umfang
- Flächeninhalt
- Gleichmäßigkeit der Radiuslängen
- Kompaktheit (Umfang²/Flächeninhalt) - 1)
- Konkavität des Rands (wie stark ist der Rand nach innen gewölbt?)
- An wie vielen Stellen ist der Rand konkav?
- Symmetrie
- Fraktale Dimension (vereinfacht: wie komplex ist der Verlauf des Rands?)
Beispiel für entnommene Zellkerne
 gutartig
gutartig
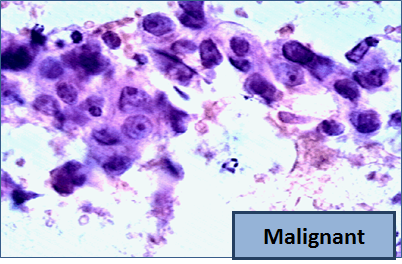 bösartig
bösartig
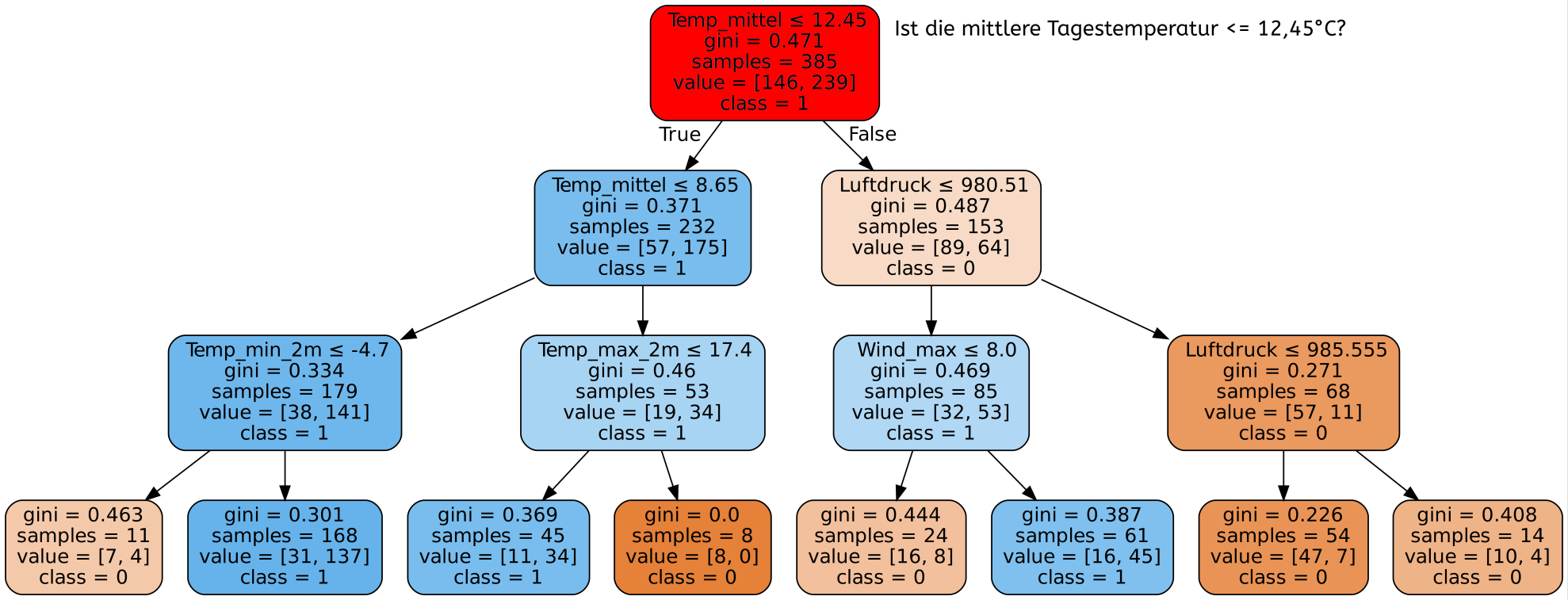
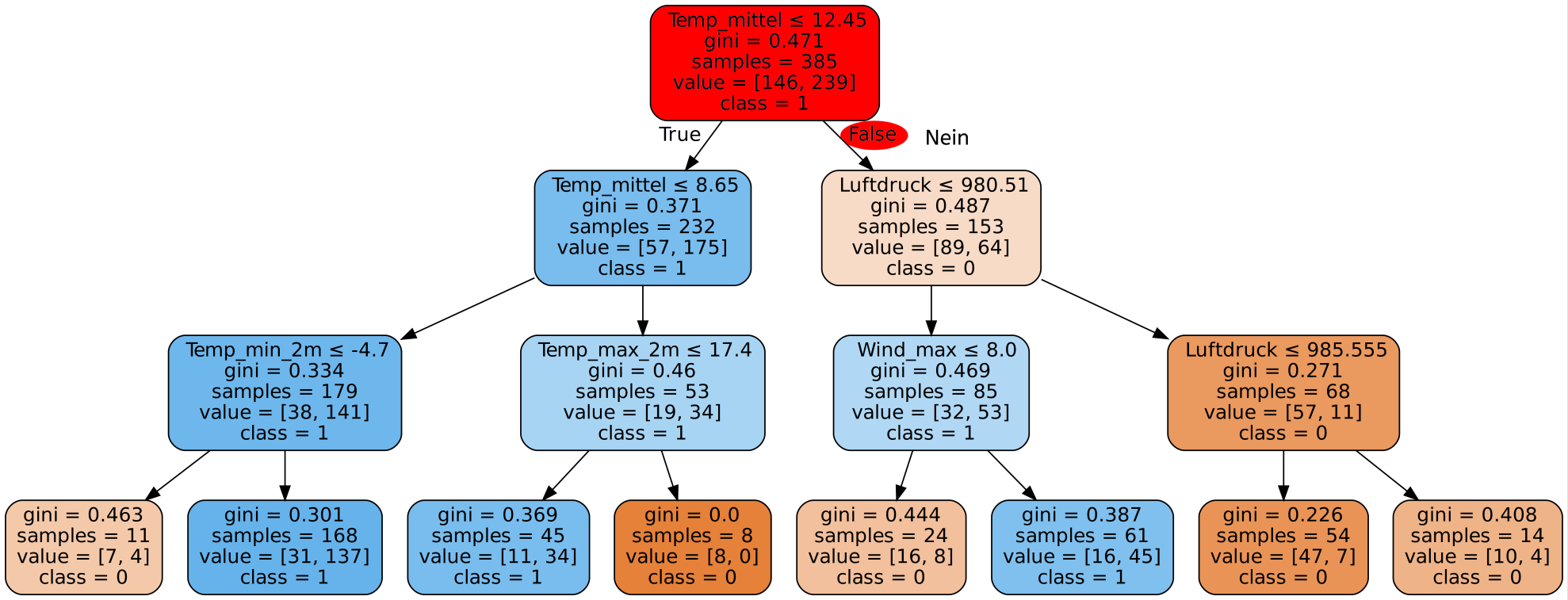
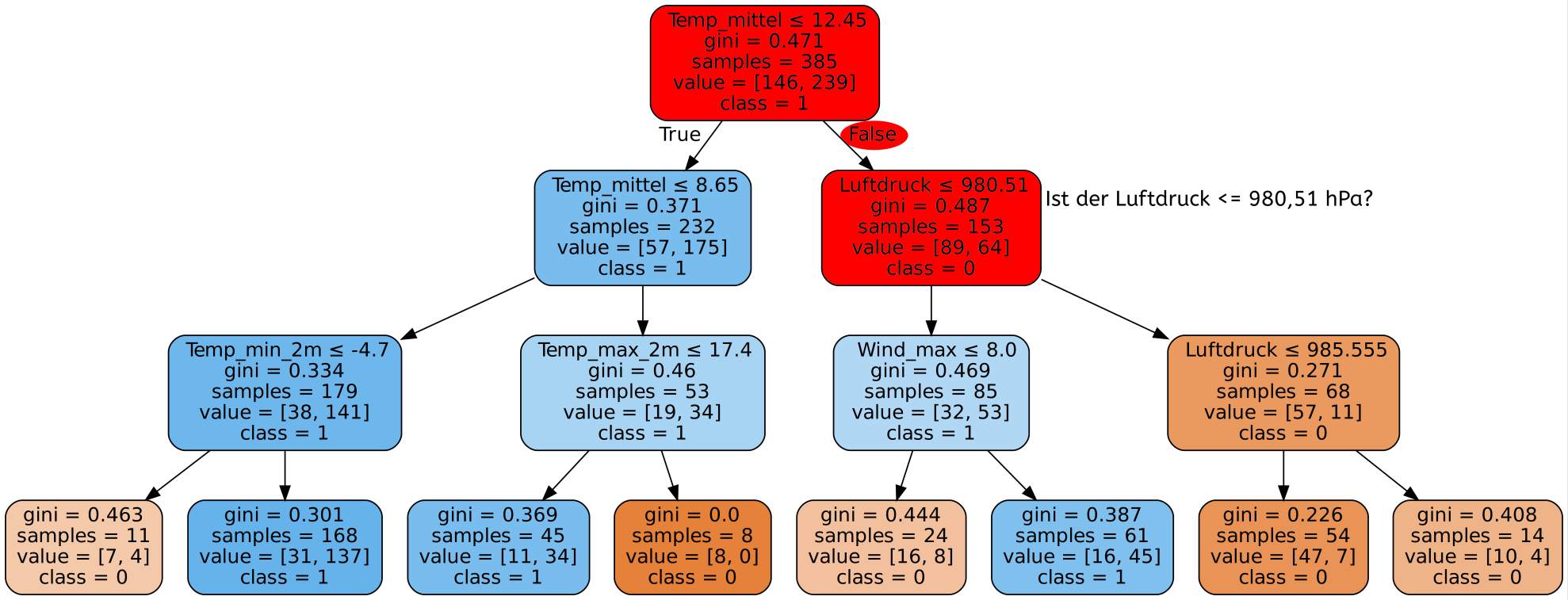
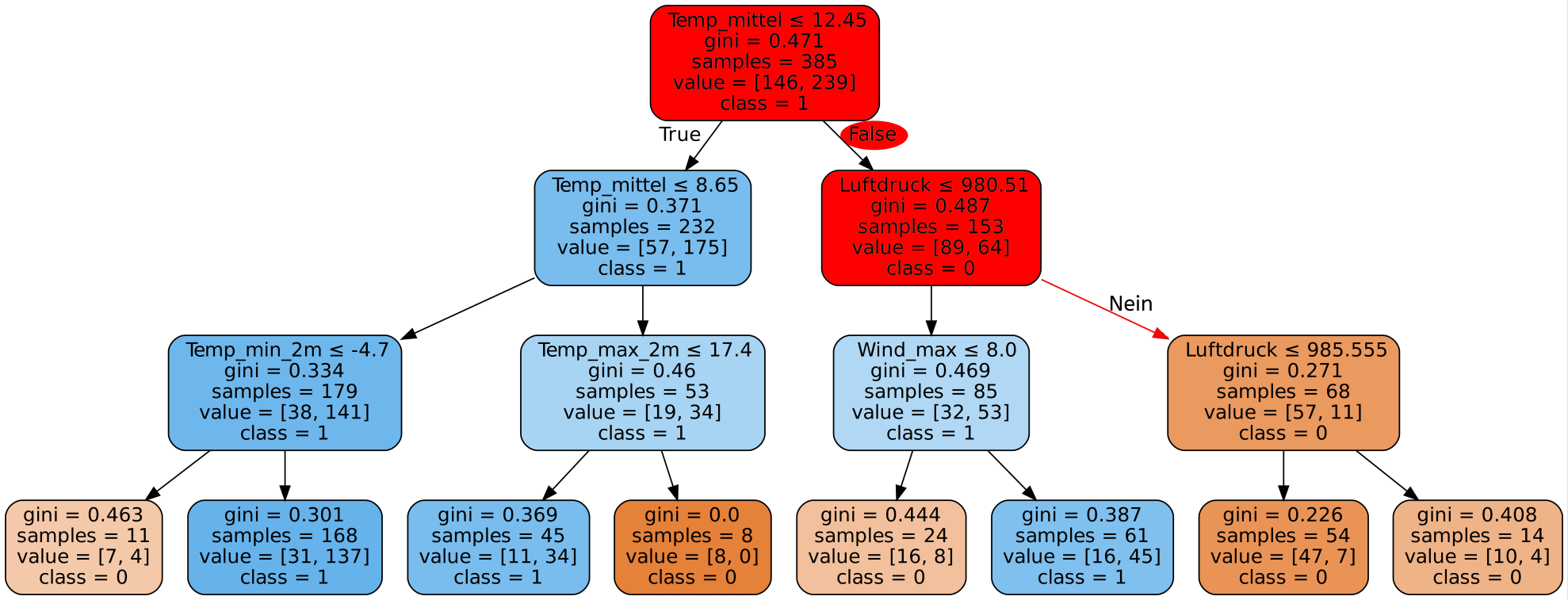
Gib hier mögliche Patientendatensätze ein und wähle einen der zur Verfügung stehenden Algorithmen. Neben dem bereits besprochenen Decision-Tree-Algorithmus stehen noch weitere Algorithmen des überwachten Lernens zur Verfügung. Da es zu lange dauern würde alle 30 Eigenschaften einzugeben, beschränken wir uns hier auf die 9 aussagekräftigsten.
Es lässt sich feststellen, dass bei manchen Eingaben je nach genutztem Algorithmus andere Diagnosen gegeben werden, obwohl die Daten exakt gleich sind. Was bedeutet das ethisch? Welchem Ergebnis sollte man mehr trauen - dem Ergebnis des Algorithmus mit der höchsten Genauigkeit oder dem Ergebnis das die meisten Algorithmen liefern?