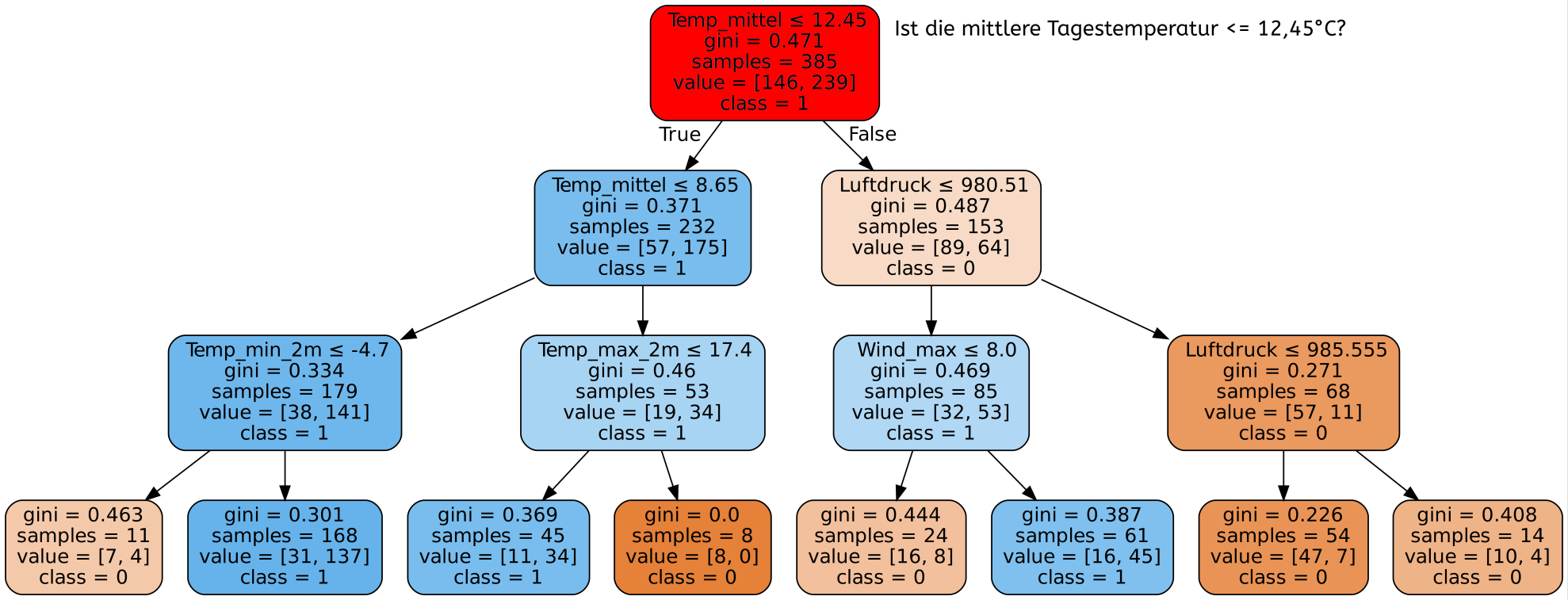
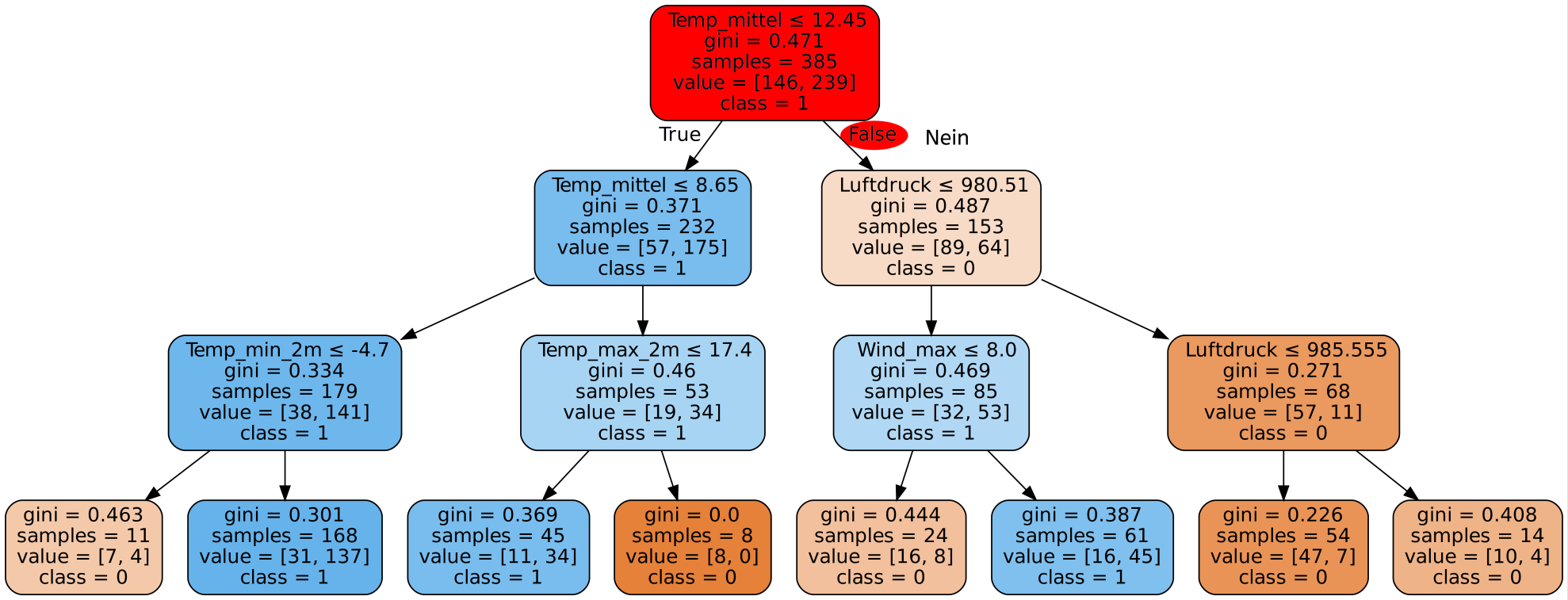
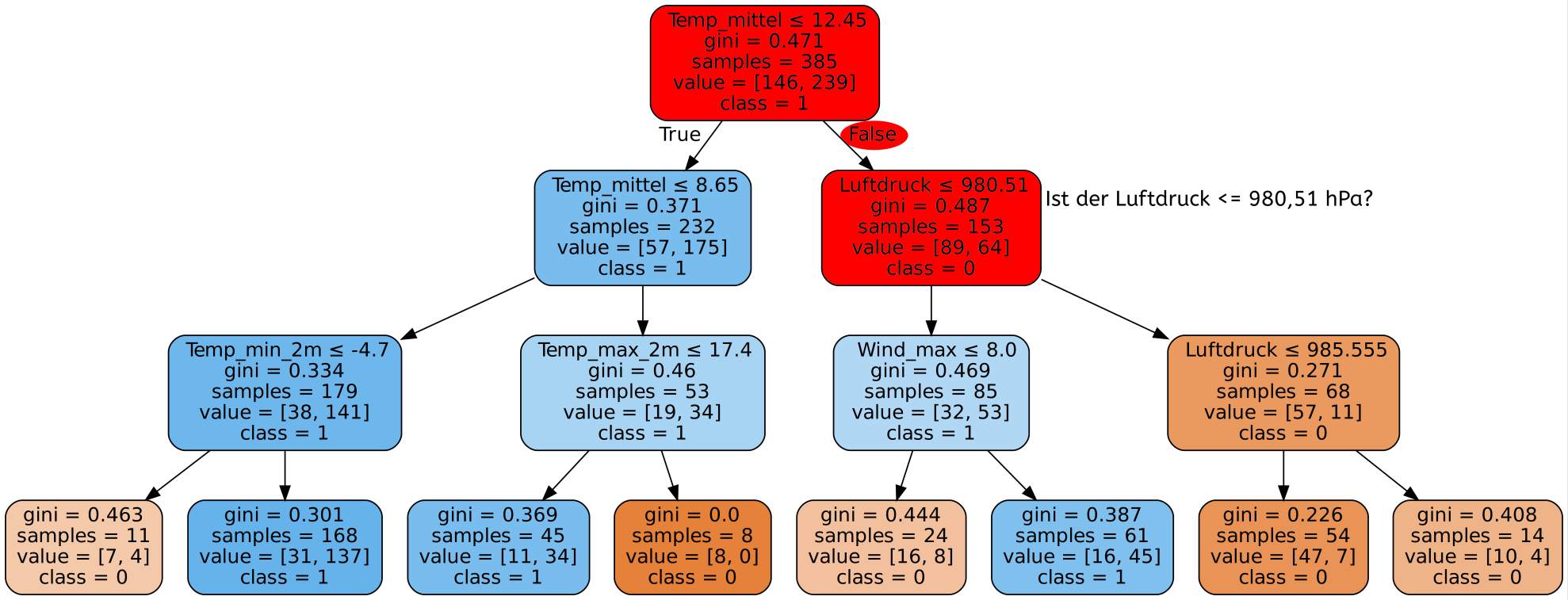
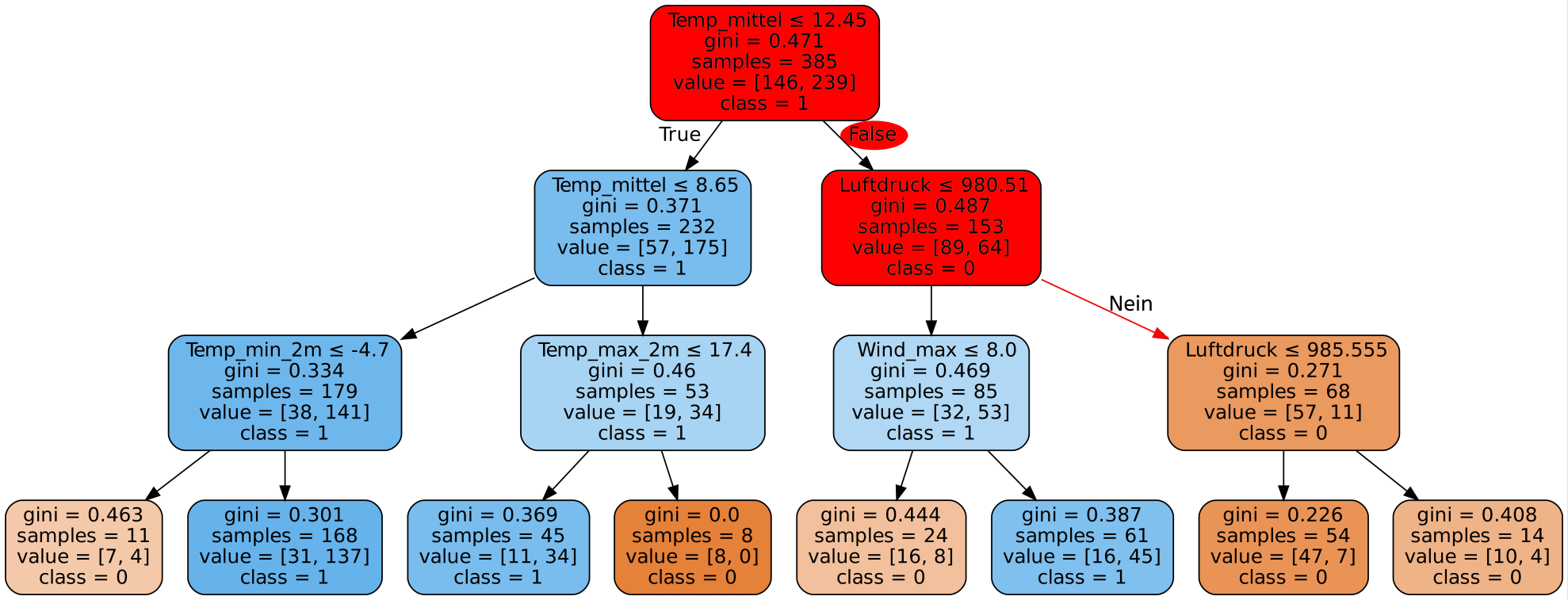
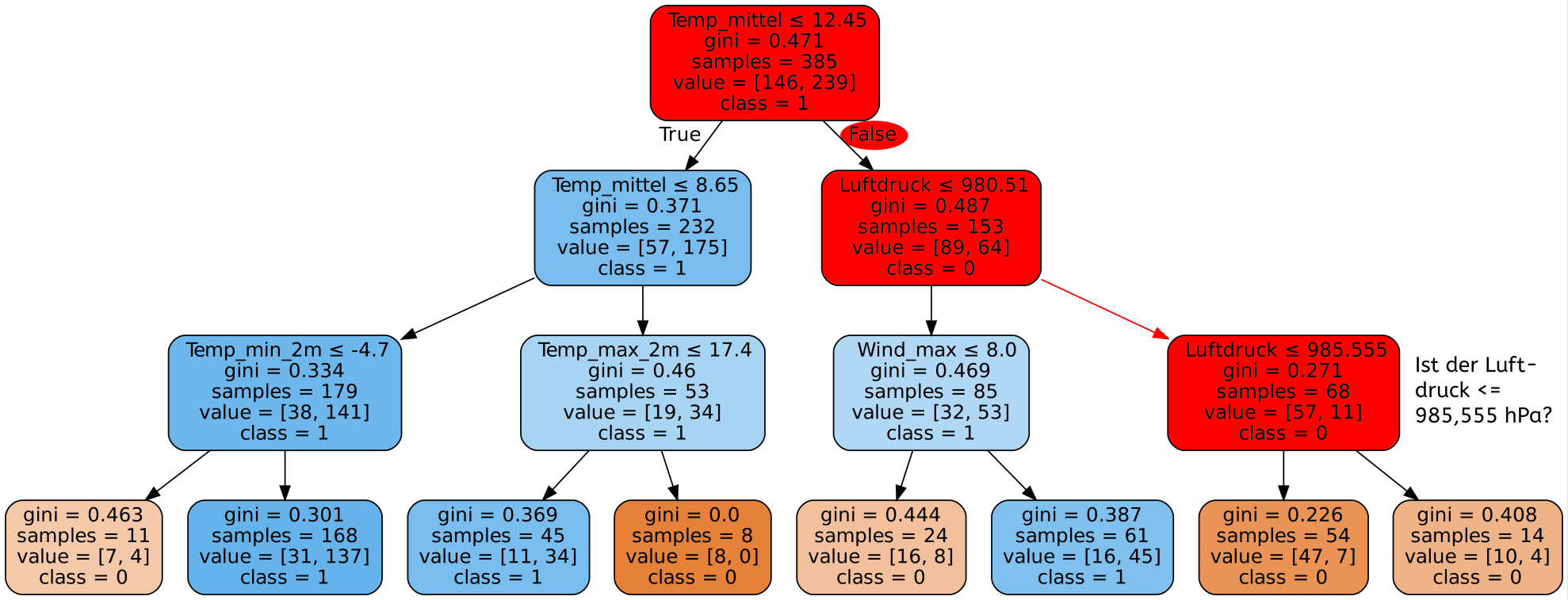
Ergebnisse
Wie gut ist unser Decision Tree? Schauen wir uns zunächst die Genauigkeit auf den Trainingsdaten an.
100%
Mit dem Decision Tree den wir gerade gesehen haben erreichen wir auf unseren Trainingsdaten eine Genauigkeit von 100%! Super! Dann sind wir ja jetzt fertig, besser geht es ja schließlich nicht. Alle Tage wurden von unserem Programm richtig eingeordnet und es wurde für jeden einzelnen Tag korrekt vorhergesagt, ob es Niederschlag gibt oder nicht.
Aber ist das wirklich ein perfektes Ergebnis?
Dazu müssen wir uns in Erinnerung rufen, wie unser Entscheidungsbaum entstanden ist. Wir haben ihn ja schließlich mit genau diesen Daten trainiert. Das heißt unserem Programm sind die Daten bereits bekannt und es ist auf diese optimiert. Verständlicherweise ist also die Genauigkeit hierbei sehr gut.
Überlegt, welche Möglichkeit wir haben, um die Genauigkeit realistischer einzuschätzen!
Wir können die extra für diesen Zweck abgespaltenen Testdaten nutzen!
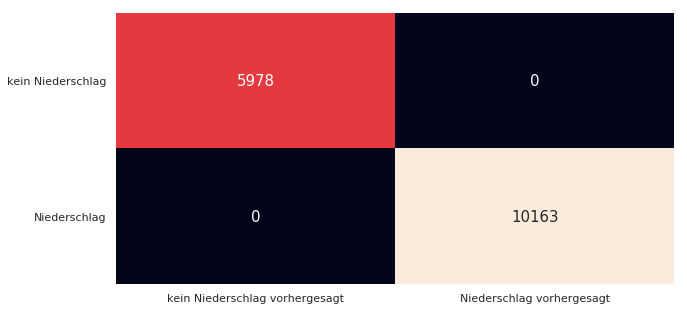
Wenn wir unser Programm nutzen um auf den Testdaten Vorhersagen zu treffen erhalten wir eine Genauigkeit von ca. 75%.

Das ist leider bei Weitem nicht mehr so gut wie auf den Trainingsdaten. Wie wir sehen, hat unser Programm für 883 Tage Niederschlag vorhergesagt, obwohl es in der Realität keinen Niederschlag gab. Ebenso lag das Programm bei 808 Tagen falsch mit der Vorhersage, dass es keinen Niederschlag gibt.
Insgesamt wurden also 883 Tage + 808 Tage = 1691 Tage von insgesamt 6918 Tagen falsch vorhergesagt! Dies entspricht dann der Genauigkeit von ca. 75%.
Eine Genauigkeit von 100% auf den Testdaten ist nicht immer wünschenswert. Oft ist dies ein Hinweis auf Overfitting. Overfitting - oder Überanpassung - bedeutet, dass der Entscheidungsbaum zu sehr auf die Trainingsdaten angepasst wurde. Dadurch passt er zwar perfekt zu diesen Daten, er kann allerdings nicht gut verallgemeinern. Dadurch werden neue, für den Baum unbekannte Daten nicht gut klassifiziert. Dieses Verhalten kann dann auftreten, wenn neben den tatsächlich relevanten Informationen und Mustern aus den Trainingsdaten auch viele unwichtige Eigenschaften in den Entscheidungsbaum eingeflossen sind. Der Algorithmus ist also davon ausgegangen, dass ein gefundenes Muster wichtig ist und erstellt auf dieser Annahme den Entscheidungsbaum. Wenn nun aber neue Daten untersucht werden, stellt man fest, dass das Muster in den Trainingsdaten gehäuft vorkam und daher als wichtig eingestuft wurde, bei allen neuen Daten aber kaum auftritt und damit der Entscheidungsbaum für die neuen Daten nicht optimal ist. Aufgrund des großen Unterschieds in den Genauigkeiten können wir davon ausgehen, dass der von uns erstellte Entscheidungsbaum zu sehr an die gegebenen Trainingsdaten angepasst ist.